#푸푸놀이터
Flux 모델을 가볍게 사용할 수 있는 GGUF를 설치해 보겠습니다. GGUF는 기존 Flux 모델 크기의 절반 정도 수준이며, 낮은 vram 에서도 구동이 가능하게 만들어졌기 때문에, 로컬 PC사양이 낮은 환경에서도 Flux 생성이 가능합니다.
기존 Flux 모델 구동에 어려움이 있으셨거나, 빠르게 결과물 만들고 싶다면 GGUF를 설치해보세요.
설치 방법 및 워크플로 셋팅방법, 그리고 사용 방법을 어렵지 않게 순서대로 자세히 설명해 놓았습니다.
차근차근 따라하시면서 설치해보세요~~
1. GGUF 파일 다운로드
1) 링크를 이동합니다.
ComfyUI - GGUF 관련 내용은 아래 Github 링크에서 확인할 수 있습니다.
https://github.com/city96/ComfyUI-GGUF
GitHub - city96/ComfyUI-GGUF: GGUF Quantization support for native ComfyUI models
GGUF Quantization support for native ComfyUI models - city96/ComfyUI-GGUF
github.com

2) GGUF 버전에 맞게 링크를 클릭해줍니다.
| - dev : 20-50 step 으로 기본이 되는 모델. - schnell : 4 step 으로 고속 추론을 위한 모델. (터보나 라이트닝과 유사 함, 속도가 빠름) |
- 로컬PC 사양이 높지 않다면 schnell 을 추천합니다.

3) 링크를 클릭하고 이동하면, File and versions 를 눌러줍니다.

- Flux - GGUF 양자화(Quantization) 모델에는 다음과 같은 유형이 있습니다.
- 각자 로컬에 맞는 양자화 모델 선택 기준으로 알려드리겠습니다.
- Q - 뒤에 오는 숫자가 높아 질 수록 성능이 높다고 생각하시면 쉽습니다.
| 양자화 모델은 로컬에 설치된 그래픽카드의 vram 기준으로 선택하시면 됩니다. Q8 (vram 24GB 이상) : Flux - fp16 모델에 용량은 절반이지만, fp16과 가장 근접한 결과를 보이는 모델입니다. Q6 (vram 16GB 이상) : Q8 유사하게 잘 나오는 모델입니다. Q5 (vram 12GB 이상) : 용량과 성능이 가장 적절한 모델입니다. (Q5_1 추천) Q4 (vram 10GB 미만) : Q4 까지는 결과물이 잘 나옵니다. Q4 이하는 추천드리지 않습니다. (Q4_0 추천) Q3 (vram 10GB 미만) : 로컬 PC의 하드웨어 성능이 부족한 경우 사용합니다. |
4) 다운로드된 파일은 Unet 폴더에 넣어줍니다.

5) 링크에서 t5_v1.1-xxl GGUF 의 링크로 이동합니다.

- GGUF 용으로 t5_v1.1-xxl 가 출시되었습니다. Flux를 설치할 때 다운로드 받았던 t5_v1.1-xxl 를 사용하셔도 되고, 사이트에서 "Qx" 사양에 맞는 t5_v1.1-xxl 다운로드 받아 사용하셔도 됩니다.

- 여기도 마찬가지로 사양에 맞는 버전으로 다운받습니다.
6) 다운받은 t5_v1.1-xxl 파일을 clip 폴더에 넣어줍니다.

2. GGUF 설치하기
1) ComfyUI 를 실행시키고 Manager 를 열어줍니다.
2) Manager 에서 Custom Nodes Manager를 열어줍니다.

3) 검색창에 ' GGUF ' 라고 검색하면, ComfyUI-GGUF 라는 노드가 검색됩니다. 이 노드를 설치 합니다.

4) 설치가 완료되면, ComfyUI 를 재시작 합니다.

3. Flux - GGUF Workflow 설정하기
1) 기본 모듈에서 시작하겠습니다.

2) KSampler 세팅
| - step : 20 (dev 모델은, 20~50 사이 / schnell 모델은, 4) - cfg : 1 (Flux 모델은 cfg를 1로 놓고 Flux Guidance 에서 cfg 를 대신합니다.) - sampler : euler - scheduler : simple |
3) 바탕을 더블 클릭해서 노트 검색란에 "Flux guidance" 라고 입력하고 노드를 추가합니다.
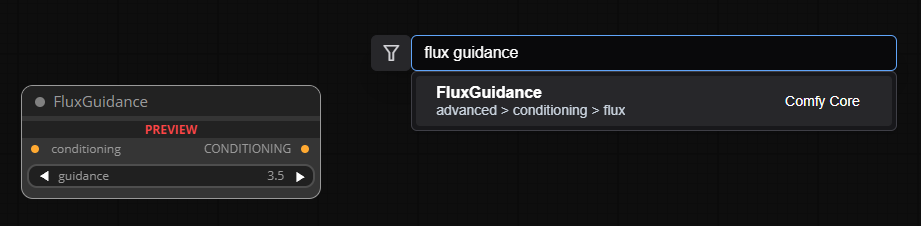
- Flux Guidance 의 왼쪽 conditioning 을 CLIP Text Encode (Prompt) 의 CONDITIONING 과 연결.
- Flux Guidance 의 오른쪽 CONDITIONING 을 KSamler 의 positive 와 연결합니다.

4) 바탕을 더블 클릭해서 노트 검색란에 "Empty SD3 Latantimage" 라고 입력하고 노드를 추가합니다.

- Empty latant image 노드를 제거하고, 방금 꺼낸 Empty SD3 Latant Image 노드의 LATANT 를 KSampler 의 latant_image 와 연결해줍니다.
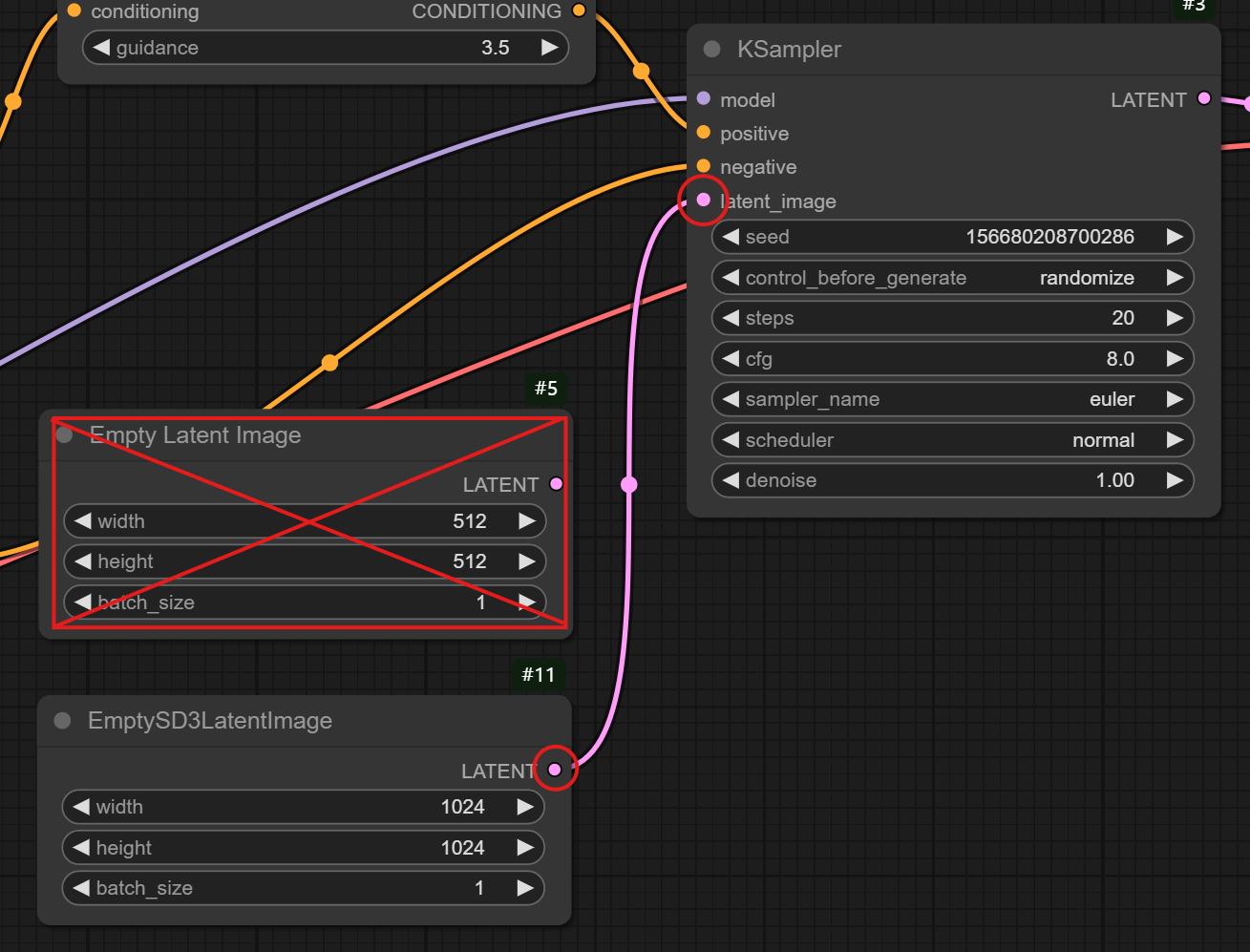
5) 바탕을 더블 클릭해서 노트 검색란에 "Unet Loader (GGUF)" 라고 입력하고 노드를 추가합니다.

- Unet Loader (GGUF) 노드의 MODEL 를 KSampler 의 model 과 연결해줍니다.

6) 바탕을 더블 클릭해서 노트 검색란에 "Dual CLIP Loader (GGUF)" 라고 입력하고 노드를 추가합니다.

- Dual CLIP Loader (GGUF) 노드 의 CLIP 을 CLIP Text Encode (Prompt) 위, 아래 두개의 노드 각각의 clip 에 연결해줍니다.

- Dual CLIP loader 노드의 파일을 선택해줍니다. ( Load Chackpoint 노드는 제거해 줍니다. )
| Clip_name1 : t5xxl_fp16 Clip_name2 : clip_l type : flux |
7) 바탕을 더블 클릭해서 노트 검색란에 "Load VAE" 라고 입력하고 노드를 추가합니다.

- Load VAE 노드 의 VAE 를 VAE Decode 노드의 vae 에 연결해줍니다.

8) 노드를 정리합니다.
- Clip text encode (prompt) 노드 상단 바 부분에서 오른쪽 마우스를 누루고 Colors 를 클릭하고 원하는 색상을 선택해줍니다. 보통 프롬프트는 녹색, 부정프롬프트는 빨간색을 사용합니다. 취양에 따라 선택해주세요.

- Flux는 부정프롬프트(Negative Prompt)를 사용하지 않기 때문에 "부정 프롬프트 노드 Clip text encode (prompt)" 는, 내용을 지우고 상단 왼쪽 동그라미를 클릭하여 작게 만들어 줍니다.

- 이제 준비가 끝났습니다.
4. Flux - GGUF 사용하여 이미지 생성하기
1) Clip text encode (Prompt) 노드에 아래와 같이 입력합니다.
filmic photo of a group of three women on a street downtown, they are holding their hands up the camera

2) Unet Loader (GGUF) 노드에 모델을 선택해줍니다.
( 저는 Q8을 선택했습니다 / Laptop RTX4090 vram 16GB )

3) Empty SD3 Latant Image 노드에서 batch_size 에 몇 장의 이미지를 만들지 입력합니다.
(Vram 용량에 따라 너무 많은 장수를 선택하면 작동이 안될 수 있습니다.)

- 이미지 사이즈는 Empty SD3 Latant Image 노드의 width, height 값으로 변경할 수 있습니다.
4) Queue Prompt 눌러서 실행합니다.
- 이미지 1장당 약 40초 ~ 1분 30초 가량 소요됩니다.
- 동작 시간은 모델 및 로컬PC의 사양에 따라 다소 차이가 있을 수 있습니다.

!!완성!!
Flux 모델은 손가락 표현이 확실히 뛰어납니다. 10번 생성하면 3~4번 정도는 완벽한 손가락이 나오는 것 같습니다. SDXL 이나 다른 모델에 비해 결과물도 좋고 사용도 편합니다. 특히 GGUF 모델은, 기존 Flux 모델보다 리소스 부담이 적어서, 낮은 사양으로도 좋은 결과물을 얻을 수 있어서 좋습니다. 다른 이미지도 생성해 보면서 GGUF를 사용해보세요.
'스테이블디퓨전' 카테고리의 다른 글
| [스테이블디퓨전] ComfyUI-FLUX-GGUF 설치(3) (두 개의 Lora를 사용해서 이미지 비교하기) (2) | 2024.09.28 |
|---|---|
| [스테이블디퓨전] ComfyUI-FLUX-GGUF 설치(2) (Lora 사용하기) (1) | 2024.09.28 |
| [스테이블디퓨전] ComfyUI-MimicMotion 챌린지 댄스 동영상 만들기 (2) | 2024.09.24 |
| [스테이블디퓨전] ComfyUI-FLUX (최고의 AI생성 모델 Flux 설치하기) (1) | 2024.09.23 |
| [스테이블디퓨전] ComfyUI-ReActor 기초 01 : 사진을 이용해 사진 합성하기 (딥페이크, 얼굴바꾸기) (0) | 2024.09.01 |